June 21, 2021
by Adam Hadhazy, for SEAS Communications
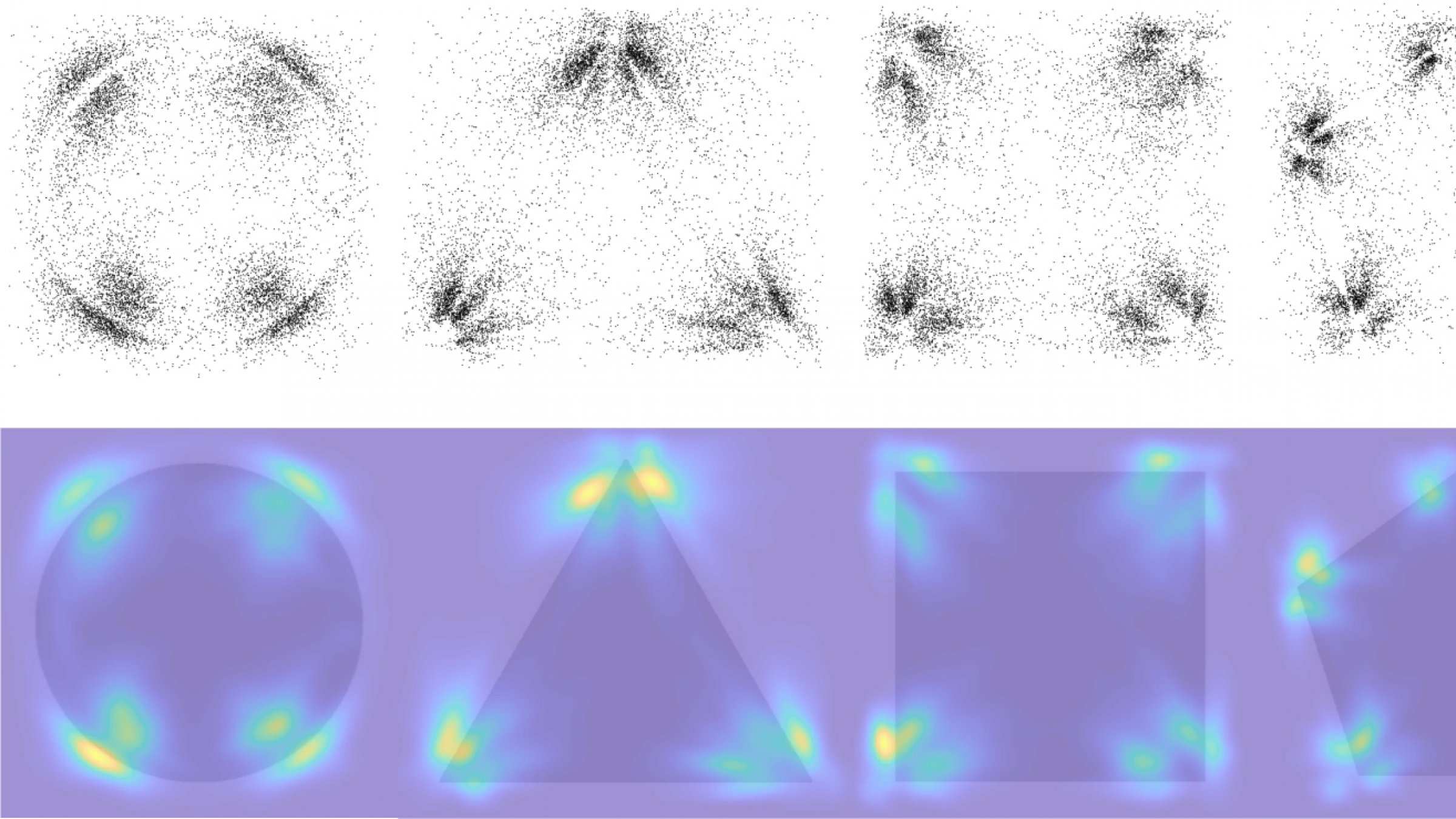
In a recent study, Princeton researchers described how people are prone to distort spatial information based on their shared expectations about a scene. The researchers studied multiple observers' recollections of the location of dots on computer screens. image provided by Griffiths et al
By having thousands of people play the visual equivalent of the "telephone game," where errors accumulate as a message is passed on, Princeton researchers have gathered new insights into the human visual system.
In a recent study, the researchers explored the distortions that bias our memory regarding the locations of objects and details within a scene. These distortions creep in because our visual system cannot process the torrent of information constantly pouring in as we view the world around us. Our brains accordingly boil things down to focus on only the most important bits.
"We have this illusion that the world just impinges on us, and we are something like a camera that records everything around us. But that's actually not true," said Thomas A. Langlois, the study’s lead author and a postdoctoral researcher in the lab of Tom Griffiths, a Professor of Psychology and Computer Science at Princeton. "We in fact have very limited perceptual resources and we cannot record every detail. So we have to constantly interpret the world around us by bringing in a lot of prior beliefs and knowledge to fill in the blanks."
The study revealed how people are prone to distort spatial information based on their shared expectations about a scene. The findings buck conventional theories that people simply fill in the blanks in their visual memory by skewing recall towards the center of objects; instead, people tend to biasedly recall points appearing near the vertices (where angles meet) of geometric shapes, for instance, as well as on the eyes and noses of faces, to give just two examples.
"In this study, we demonstrated an experimental technique that reveals the shared, prior beliefs people bring that are hidden from view but are an essential part of how vision works," said Griffiths, the senior author of the study published in the Proceedings of the National Academy of Sciences.
The telephone-like game revealed these patterns of encoding visual memory by tasking participants with recalling the location of a red dot one second after it disappeared from an image on a computer screen. Due to imperfect human spatial memory, participants were slightly off in their recollection of the exact location of that first dot. These imperfect answers then served as the locations for second dots, seen by a new round of participants unaware of the original dots' locations. The second set of participants likewise introduced some error in their recall response, with their response then serving as the stimuli for a third round of participants, and on into a fourth round, and so on.
Just like in the telephone game, the original message (or location of the dot, in this case) became increasingly garbled, but in a way that reflected the distortions people commonly make. For instance, if Participant 1 recalled a dot closer to a triangle corner than it actually was, Participant 2 was also likely to misremember the dot as being even closer to the corner, and so on, such that after enough rounds, the location of the dot settled into the corner.
"Remarkably, what you see is that people tend to produce the same kinds of errors," said Langlois. "You see the recall errors start to migrate towards these landmarks and eventually converge as you go through many iterations."
Most studies that have previously tried to get to the root of visuospatial memory bias have had small numbers of participants go through single iterations or rounds of a recall challenge. Those results varied wildly from person to person, leading to averages being drawn that painted the middle of objects as apparent magnets of skewed recall.
The Princeton-led study, however, recruited a huge pool of participants—9,202 in all—via the Amazon Mechanical Turk crowdsourcing platform. In total, those participants ran through 20 iterations of 85 separate dot placement experiments. The massive amount of collected data newly showed that the visual system more selectively and efficiently allocates the encoding of memory with variable precision across objects in space—for instance, toward certain landmarks—rather than with the fixed encoding precision assumed based on prior studies.
From these findings, the research team proposed what they call an efficient encoding model. The model holds that because of the brain's finite resources ultimately limiting our ability to store all regions of a visual scene in memory with equal accuracy, there is an optimal trade-off between memory-encoding resources and precision. "We encode different regions of space with changing degrees of precision and accuracy," said Langlois.
As a future research angle, Langlois would like to examine people's visuospatial memory biases in three-dimensional spaces such as virtual reality environments, instead of the merely two-dimensional screens used in the current study.
By offering new insights into how people visually process information, the findings might help in the design of more effective user interfaces for computers and other devices. Another application area, Langlois said, is enhancing the performance of machines that interact with humans. The robots' programming could benefit from a greater understanding of the inferences people make about a visual environment when navigating it.
"There is a lot more we hope to learn through using this telephone game technique about the hidden beliefs that shape our perception from moment to moment," said Langlois.
The Princeton researchers collaborated with Nori Jacoby of the Max Planck Institute for Empirical Aesthetics, who was co-first author with Langlois, and Jordan Suchow at the Stevens Institute of Technology on the study. The work was supported by the National Institutes of Health and the Defense Advanced Research Projects Agency.